
A Status Check on Hallucinated Case Law Incidents
In September 2025, The Guardian reported about a lawyer in Australia having faced sanctions due to false citations. These citations were not false due to a human error or an intention to deceive; they were false because they were incorrectly generated by a large language model. These language models are today the mainstream of generative artificial intelligence (AI). But what happened to the lawyer who used these models incautiously? The lawyer apologized but was still stripped of his ability to practice as a principal lawyer.
The Australian case is not an isolated incident. In fact, incidents are piling up throughout the world. Dismayed by the situation, Joe Patrice wrote recently that each and every “time a lawyer cites a fake case spit out by generative AI, an angel gets its wings”. With his sarcastic comment as a motivation, it is a good time for a status check driven by a question: how many angels have gotten wings? Another relevant question is: what happened to the lawyers who gave wings to angels? The two questions are relevant for practitioners of law, legal scholarship, and higher education, but they also allow to reflect about the increasingly tense relationship between technology, professional practice, and societies in general.
Hallucinated Law
It is well-known that large language models hallucinate. They often produce plausible falsehoods with confidence. As OpenAI’s developers wrote about a month ago, hallucinations are mathematically inevitable with the current large language models. Regarding more theoretical interpretations, there is also a debate whether the term hallucination is appropriate. For instance, some authors have argued that the philosopher Harry Frankfurt’s famous ideas describe these errors better because the term hallucination is misleading already in a sense that also correct outputs from large language models are without any regard to truth.
To put terminology aside, what does the recent research literature say about the prevalence of hallucinations in the context of law? The answer is simple: existing empirical evaluations indicate a substantial probability of both popular and specialized large language models to hallucinate citations and generate other errors. For instance, a recent paper found that the law-specific LexisNexis’ AI and Thomson Reuters’ Westlaw AI both hallucinated between 17 percent and 33 percent of the time. Other papers have reported even more alarming numbers. For example, another recent paper reported a 58 percent hallucination rate when different types of errors were accounted for. The errors considered in the paper range from non-existent cases and incorrect authorship to erroneous dispositions about decisions and false factual background statements.
Similar results apply to science in general, regardless of a discipline. Without a particular need to point out more academic evaluation articles, it suffices to allege that many – if not most – academics who have peer reviewed manuscripts in recent years have probably encountered and possibly detected hallucinated citations and related AI-induced falsehoods. Unfortunately, initial probes indicate that automated detection seems hard for hallucinated citations and references.
Therefore, it seems that hallucinated citations and bibliography entries are something we just have to live with in science. The same applies to the avalanche of junk science filling submission systems of journals and wasting scarce resources of editors and peer reviewers. By assumption, much of the junk is today generated with large language models. Drawing again from Frankfurt’s ideas, some authors have even argued that we are already in the midst of a crisis of epistemology to which AI and computing in general both respond and contribute. With this background in mind, a hypothesis for the subsequently presented status check is that a strong growth trend is present also outside of the ivory towers.
The Status Check
The status check is empirical and quantitative. Data comes from Damien Charlotin’s catalog for hallucinated case law incidents, drawn particularly in the United States but also elsewhere. The incidents are about those explicitly detected by courts. Beyond that remark, the data collection details are not openly documented and thus a grain of salt should be taken particularly about a few numerical details soon presented. However, at the time of writing, already as many as 719 incidents have been cataloged. Even with inaccuracies, the amount is sufficient for answering to the first hypothesis. The over four hundred incidents also motivate another hypothesis: the sanctions imposed have supposedly been moderate because the volume of hallucination incidents is increasing as per the first hypothesis, the artificial intelligence boom and the associated hype are both still peaking, and guidance seems to be generally missing.
Without further ado, Fig. 1 visualizes the monthly counts of the incidents cataloged. The first hypothesis holds: there has been a strong growth trend in hallucinated case law incidents from May 2023 to mid-December 2025. When considering the ongoing year 2025, there has not actually been a mere growth trend but an explosion of hallucination incidents.
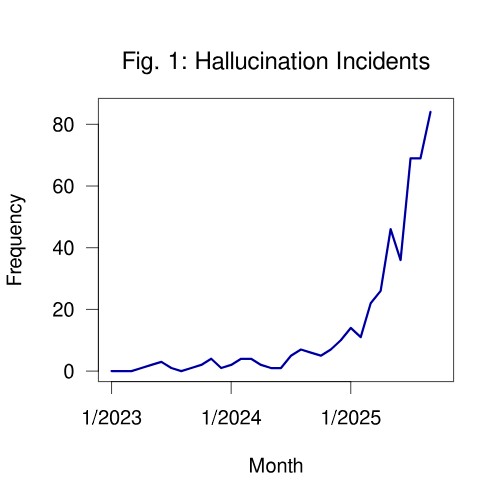
A few numerical details give a little substance for the growth trend – or the explosion. Regarding the types of hallucinations, fabricated citations lead the ranking, as could be expected. Other frequent incident types include misrepresented precedents, false quotations, and misrepresented authorities. Although a particular large language model was not explicitly identified in the majority of the incidents, all common models are still well-represented; among them ChatGPT, Copilot, Claude, Westlaw AI, and Lexis Nexis’ AI. Given that also Grammarly is present, even innocent use cases, such as automated proofreading, are not without risks.
Turning to the other hypothesis, according to regular expression searches, about 28 percent of the incidents have resulted in warnings for the lawyers involved. No sanctions were imposed in about 2 percent of the incidents and another 2 percent involved dismissals of the cases brought to courts. That said, monetary penalties have been relatively common; about 19 percent of the hallucination incidents have involved fines.
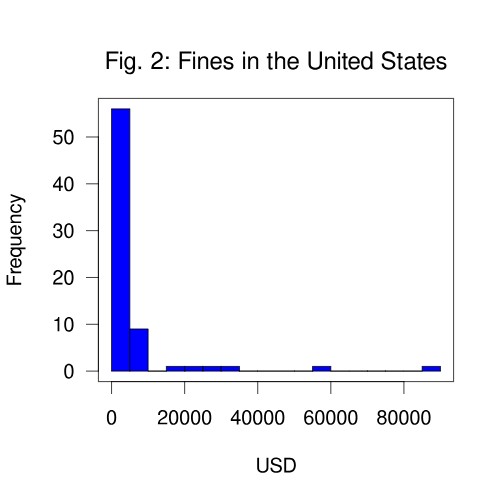
Fig. 2 shows a histogram of the monetary amounts in the 51 fines imposed in the United States. As can be seen, most fines have been relatively moderate; the majority are below $5,000 (USD), but there are also a few larger fines above $20,000 USD. Comparable amounts are present in a few other countries having imposed monetary penalties. Even though sanctions are sanctions even when they are only moderate, the second hypothesis can be argued to also hold: only moderate sanctions have been imposed, supposedly because of the growing incident rate and a general uncertainty regarding what to do with angels gaining wings.
Conclusion
Hallucinated case law incidents are exploding at the moment, but the sanctions imposed for the lawyers involved in the incidents have only been relatively moderate thus far. To return to the Australian incident, Juliana Warner commented that the incidents raise severe concerns, but a strict prohibition might hinder innovation and access to justice, being also implausible to enforce due to the widespread use of generative AI. A similar conclusion might be reasonable for science.
The growth trend seems alarming but it could be also argued that the 719 cases thus far cataloged by Charlotin are just a drop in the ocean of litigation cases brought to courts in the United States every year. The amount would likely still be small relatively speaking when considering a possibility of hallucination cases not detected by courts. That said, this point is exactly what makes hallucinated case law and hallucinated law in general dangerous. Analogously to false citations in science, it may be difficult to correct hallucinated case law later on. In the future, it could even be that a future decision by a judge will be based on something that is blatantly untrue or even non-existent.
In other words, law and science share a similarity in that they both build upon existing artifacts, whether existing law or knowledge. Thus, it must be also asked: what will the long-run consequences be? If the epistemic crisis is real already today or will be real in the future, will it lead to the eventual corruption of both science and law? These questions must be asked, although no one knows the answers. In the meanwhile, scientists, scholars, and lawyers alike should seek both technical and practical means to navigate and work under the epistemic uncertainties caused by large language models and artificial intelligence in general. A good starting point would be to frankly and openly communicate the limitations of large language models. Although communication and education alone are not likely sufficient, they might still at least flatten the growth curve of hallucinated case law incidents reported in this status check.



















































































