Storify is Dead. Responsible Data Stewardship Must Live
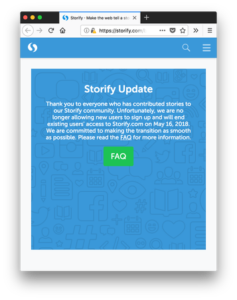 Storify is dead The service, which let you take social media content like Twitter and Facebook posts and aggregate them together into stories, announced that they’ll be shutting down and deleting all content as of March 16th, 2018. It’s not as bad as some platform shutdowns – there is notice and at least you can export your own content (one story at a time) – but it’s still a reminder of how vulnerable user-generated content can be online.
Storify is dead The service, which let you take social media content like Twitter and Facebook posts and aggregate them together into stories, announced that they’ll be shutting down and deleting all content as of March 16th, 2018. It’s not as bad as some platform shutdowns – there is notice and at least you can export your own content (one story at a time) – but it’s still a reminder of how vulnerable user-generated content can be online.
This hits all users hard. Within academia, Storify seems to be the go to to document controversy, or more commonly, conferences (say, the proceedings of an online conference or the hard work that went into documenting a presidential address). And why not? It’s an intuitive platform, far better than grabbing screenshots, and the other standard method – embedding Tweets in say a blog post – is equally vulnerable to an external service, that of Twitter itself, changing its access, model, or failing altogether.

This has been reposted from Ian Milligan’s blog, where it appeared under the headline, “The Death of Storify, Difficult Alternatives, and the Need to Steward our Data Responsibly.” It appears here under a Creative Commons Attribution-ShareAlike 4.0 International License.
So what should we do?
The first hot take is that it underscores how when we spoke about “archiving” a hashtag on Storify, we weren’t really doing anything resembling that term. We were temporarily parking it on a free site until it inevitably closed.
The second big point, to me, is to use this as an opportunity around how we could move forward as a field.
Let’s imagine we’re a scholar who wants to document a hashtag (and by this I mean for a talk, conference or event, not the large-scale DH use cases). What can they do? And where could they, if we don’t love the easy go-to solutions, turn to for help?
1) Embed Tweets Themselves in Content. This is a decent medium-term solution. Most content management systems allow you to do this. Twitter supports this too. You can find it on the Twitter card itself in the interface, and then you get a handy code you can paste.
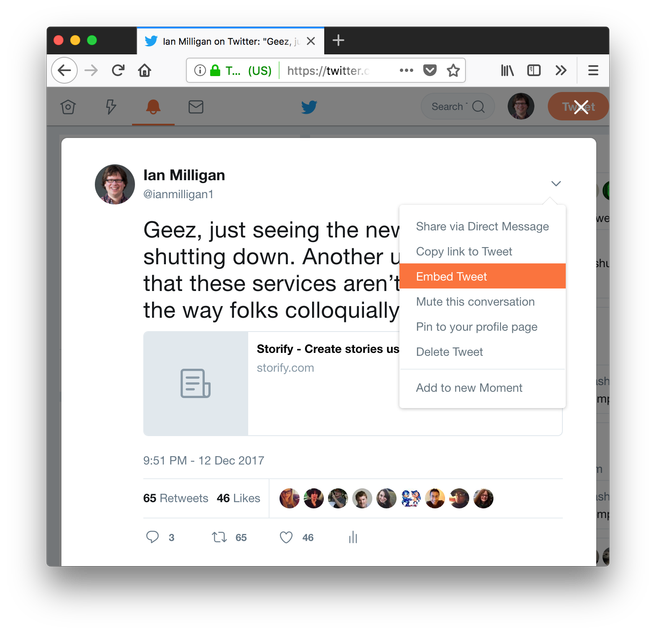
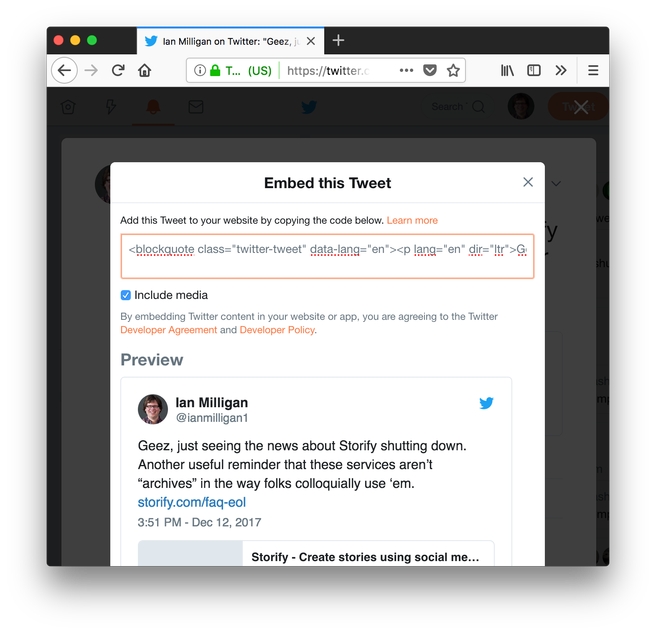
I pasted that code here, and voila, you can see the Tweet in all its pretty goodness.
Geez, just seeing the news about Storify shutting down. Another useful reminder that these services aren’t “archives” in the way folks colloquially use ‘em. https://t.co/fq7t4Lyd0G
— Ian Milligan (@ianmilligan1) December 12, 2017
But let’s not lie, embedding isn’t a magic bullet. There’s a few problems with it:
- Embed code is alienating. If you’re used to playing around with HTML, it’s not a big deal to paste a snippet in. If you’re not, it’s weird. “Find the HTML tab at the top of the WordPress post,” or whatever CMS rules the work. Paste it. Maybe it’ll work, maybe it won’t, etc. There’s a reason services exist to hide the raw language.
- It’s outsourcing the content to Twitter. That beautiful Tweet you see above is reliant on looking nice thanks to the existence of Twitter.com. It’s not all bad. The text of the Tweet is included in the embed code, so if Twitter goes bellyup, you could still find out what I was talking about. But the image, retweets, favourites, etc., all that fun stuff, is all living somewhere else.
- It’s a pain in the ass compared to Storify. Storify was easy, this is pretty tedious.
2) Save the Tweet data in a raw form. If you really want to preserve a Tweet, there’s always the (ever-changing) Twitter API. Using a tool like twarc, you can grab content in the raw data form. Nick Ruest and I wrote an article about using twarc to document the Canadian election in 2015. This gives you a ton of rich information that you can use to reconstruct the tweets, see who was tweeting to who, think about the network dynamics, follower/followee numbers, influence, etc. etc. etc. It’s fantastic.
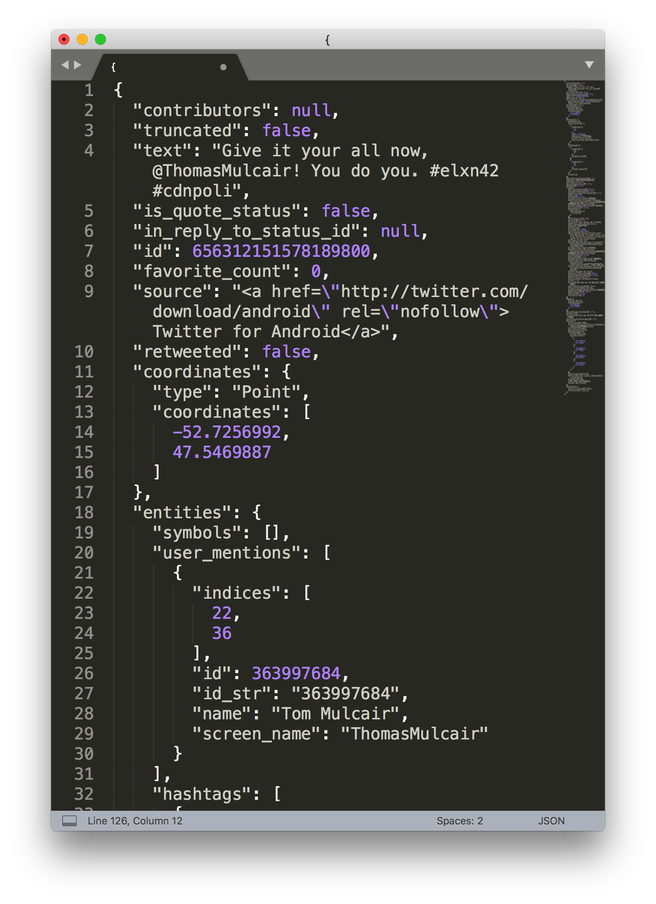
But the downside:
- The data comes in JSON format, or maybe a CSV. If I wanted to do some text analysis work, this is great. If I want to write a nice blog post about how people responded to a conference, it’s a bit of overkill.
- Services to collect are rare. I love the DocNow tool and basically have a “spin it up on AWS” command in my back pocket. But it’s a prototype, and I’m never sure if the running versions that are out there are game to share with folks… and the problem of exporting to content is still there.
3) Use another third-party service. There are other services similar to Storify out there. Twitter moments is probably the closest, although it doesn’t quite have the same feel. Indeed, Shawn Jones has a great post on alternatives to Storify that’s worth revisiting right now. But the problem with that is the same as with Storify… the dangers of having your data just hanging out there, vulnerable to another shift.
So what to do? Why don’t they turn to the library for help?
If I have data that I want to preserve, what do I do? Shove it on a hard drive in the corner of my office? Give it to the proprietary cloud that University of Waterloo has given me 5TB on, that I apparently lose access to immediately upon my employment ending here (and really, will it stick around until my anticipated retirement year of 2048)? Put it all on some strange .edu startup that has some free-mium business model?
No, I turn to parts of the university and scholarly landscape that have made the preservation, description, and accessibility of data part of their core mandate: libraries and librarians/archivists. This might be our consortial Scholars Portal Dataverse here in Ontario, Zenodo, or an individual universities’ institutional repository; in my own personal case, it’s a deep collaboration with a librarian/archivist on the conception, execution, and day-to-day activities of our own projects.
That’s not to be utopian: libraries don’t have some sort of magic spell that means they’re impervious to destruction. I can’t just put my data in one of those and not actively care about it, whether it’s from trying my best to make sure we can show value for the investments governments make (and working as hard as I can, in my own way, making sure we don’t get apathetic about these politically), or ensuring that the folks who actually build and maintain systems to preserve this data get respected by administrators, but it’s a bit more in my wheelhouse than Storify would be.
BUT if we truly care about data – from the social media logs of a conference, to the records of a federal election – we need to treat it with respect. And that means turning to people who are trained in this.
The first step is getting people to think about:
- If you care about your data, what’s the best way to save it?
- How would you feel if this platform failed and disappeared with relatively minimal notice?
- Have you considered a more sustainable approach to this?
Maybe it’s helping people embed tweets, or grabbing the JSON behind an event, or screenshotting, or coming up with a Plan B if a service dies. If I had more time, it’d be interesting to explore creating some sort of service that can do what Storify does – quickly and efficiently arrange Tweets and present them – but save them in a sustainable format. But mostly, the answer needs to be that if we’re talking about “archiving” or “preserving” a conference hashtag, or event, we need to turn to the professionals.
And of course, they need to be ready for it too. At a lot of universities, I doubt it’s straightforward to just reach out and learn how to steward data. Some don’t have institutional repositories, some don’t have central contact areas, some you’d probably send an e-mail and get bounced around a million times. When scholars “archive” their data in strange places, it’s not all their fault.
But our cultural data should be stewarded by those who steward data because they recognize its importance, not just its potential for monetary value.
How could we make that happen? I guess it makes me wish we had a scholarly commons at our university like several others do: a place where people could not only go for advice about like “what do I do to preserve a conference hashtag now that my go-to tool is dead,” but a place that was baked into the scholarly ecosystem from the get go. Where you wouldn’t have to reinvent the wheel and turn to some zany startup to get something done, but you’d feel like you could comfortably and quickly chat about a problem.
Chances are there are folks in our library, or elsewhere on campus, that have fantastic ideas about these things. Let’s make sure we can all find each other.






















































































